
豆包大模型团队开源VideoWorld:纯视觉驱动的AI模型新突破
来自豆包大模型团队官方公众号的最新消息显示,由北京交通大学与中国科学技术大学联合研究,并由豆包大模型团队主导的 “VideoWorld” 视频生成实验模型,已正式宣布开源。
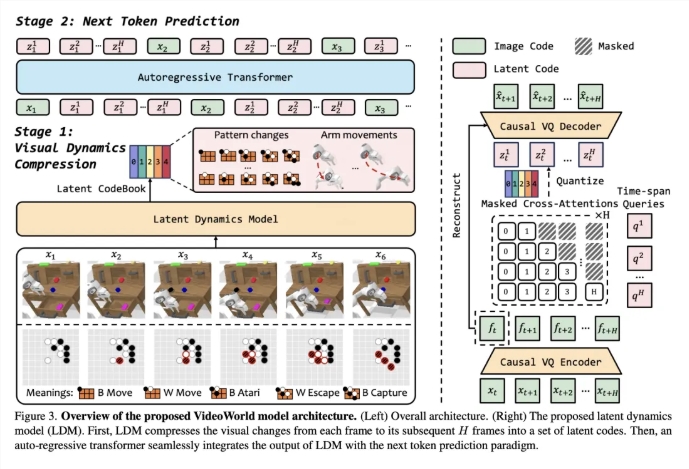
该模型最显著的特点在于,它摒弃了对传统语言模型的依赖,完全基于视觉信息来实现对世界的认知和理解。这项创新性研究的灵感源自李飞飞教授在 TED 演讲中提出的观点,即 “幼儿无需依赖语言便可理解真实世界”。
“VideoWorld” 通过深入分析和处理海量的视频数据,从而获得了进行复杂推理、规划和决策的能力。研究团队的实验结果表明,即使在仅有 300M 参数的轻量级配置下,该模型也能展现出卓越的性能。与当前依赖语言或标签数据的模型不同,VideoWorld 具备独立进行知识学习的能力,尤其在折纸、打领结等需要直观理解的复杂任务中,能够提供更便捷的学习方式。
为了全面评估模型的有效性,研究团队特别构建了围棋对战和机器人模拟操控两种实验环境。围棋,作为一项极具策略性的游戏,能够有效检验模型的规则学习和推理能力;而机器人任务则侧重于考察模型在控制和规划方面的表现。在训练过程中,模型通过观看大量的视频演示数据,逐步建立起对未来画面变化的预测能力。
为了显著提升视频学习的效率,研究团队创新性地引入了一种潜在动态模型(LDM),其主要目的是压缩视频帧之间的视觉变化,从而高效地提取出关键信息。这一方法不仅大幅减少了冗余信息,还显著增强了模型对于复杂知识的学习效率。得益于这一创新技术,VideoWorld 在围棋和机器人任务中均表现出色的能力,甚至达到了专业五段围棋选手的水平。
核心要点:
- 🌟 “VideoWorld” 模型无需依赖语言模型,仅凭视觉信息即可实现知识学习。
- 🤖 模型在围棋和机器人模拟任务中展现出强大的推理和规划能力。
- 🔓 该项目代码与模型已开源,欢迎广大开发者参与体验与交流。
豆包AI工具地址:【点击登录】
更多AI行业最新资讯新闻信息请关注AI人工智能网站--AITOP100平台--AI资讯专区:https://www.aitop100.cn/infomation/index.html










