点击参加51CTO网站内容调查问卷
译者 | 布加迪
审校 | 重楼
机器学习模型只有在生产 环境 中用于解决业务问题时才有帮助。然而,业务问题和机器学习模型在不断发展 变化 。这就 要求 我们维护机器学习, 以便 性能跟 得 上业务 KPI 。这就是 MLOps 概念的 由来 。

MLOps 或机器学习 运营是一整套 用于生产 环境 中机器学习的技术和工具。 MLOps 处理的事情 从 机器学习自动化、版本控制、交付和 监测 。本文重点 介绍监测 以及如何在生产环境中使用 Python 软件 包 来监测 模型 性能 。
监测模型性能
当 我们谈论 MLOps 中的 监测 时,它 其实 指很多 方面 ,因为 MLOps 的原则之一就是 监测 。 比如说:
- 监测数据分布 在一段时间以来的 变化
- 监测开发 环境 和生产 环境 中使用的功能 特性
- 监测 模型衰减
- 监测模型性能
- 监测 系统 失效 情况
MLOps 中仍然有许多 方面 需要 监测 ,但是 本文 重点关注 监测 模型性能。在 本文中, 模型性能 是指 模型 利用没有见 过的数据做出可靠预测的能力,用特定的度量 指标(比如 准确性、精度 或 召回率等 )加以衡量。
为 什么我们需要监测模型性能 ?为了 保持 模型预测的可靠性以解决业务问题。在 部署到 生产 环境之前 ,我们经常计算模型性能及其对 KPI 的影响 。比如说 ,如果我们希望模型仍然遵循业务需求, 基准要求是 70 % 的准确性,但低于 这个标准 不可接受。这就是 为什么 监测性能 可以保证 模型始终满足业务需求 。
使用 Python ,我们将学习如何 实现 模型监测。 不妨 从安装 软件 包 入手 。模型监测 方面 有很多选择,但是 就本文而言 ,我们将使用 名为 evidently 的 开源 软件 包进行监测。
用Python设置模型监测
首先 , 我们需要用 以下 代码 来 安装 evidently软件 包。
pip install evidently 安装完 软件 包后,我们将下载数据示例,即来自 Kaggle 的保险索赔数据。此外,我们将在进一步使用 这些 数据之前清理数据。
import pandas as pddf = pd.read_csv("insurance_claims.csv")# Sort the data based on the Incident Datadf = df.sort_values(by="incident_date").reset_index(drop=True)# Variable Selectiondf = df[ [ "incident_date", "months_as_customer", "age", "policy_deductable", "policy_annual_premium", "umbrella_limit", "insured_sex", "insured_relationship", "capital-gains", "capital-loss", "incident_type", "collision_type", "total_claim_amount", "injury_claim", "property_claim", "vehicle_claim", "incident_severity", "fraud_reported", ]]# Data Cleaning and One-Hot Encodingdf = pd.get_dummies( df, columns=[ "insured_sex", "insured_relationship", "incident_type", "collision_type", "incident_severity", ], drop_first=True,)df["fraud_reported"] = df["fraud_reported"].apply(lambda x: 1 if x == "Y" else 0)df = df.rename(columns={"incident_date": "timestamp", "fraud_reported": "target"})for i in df.select_dtypes("number").columns: df[i] = df[i].apply(float)data = df[df["timestamp"] < "2015-02-20"].copy()val = df[df["timestamp"] >= "2015-02-20"].copy() 在上面的代码中,我们选择了一些用于训练 模型 的列,将它们转换 成 数字表示,并将 数据分为 参考数据 ( data ) 和当前数据 ( val ) 。
我们 需要 MLOps 管道中的参考或基 准 数据来监测模型性能。它通常是 与 训练数据 分开 来的数据 (比如测试 数据 ) 。此外,我们还需要当前数据或模型未看到的数据 (入站数据) 。
不妨 使用 evidently 来监测数据和模型性能。 由于 数据漂移会影响模型性能,所以它也是需要监测的 对象 。
from evidently.report import Reportfrom evidently.metric_preset import DataDriftPresetdata_drift_report = Report(metrics=[ DataDriftPreset(),])data_drift_report.run(current_data=val, reference_data=data, column_mapping=None)data_drift_report.show(mode='inline') 数据集漂移
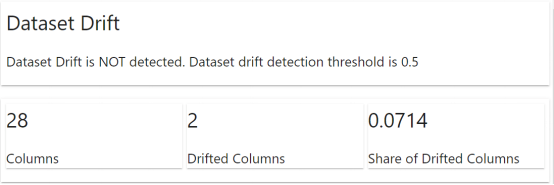
evidently软件包 将自动显示 一份报告,表明 数据集 所出现 的情况。该信息包括数据集漂移和列漂移。对于 上述 示例 而言 , 没有出现 任何数据集漂移,但是有两列 出现了 漂移。
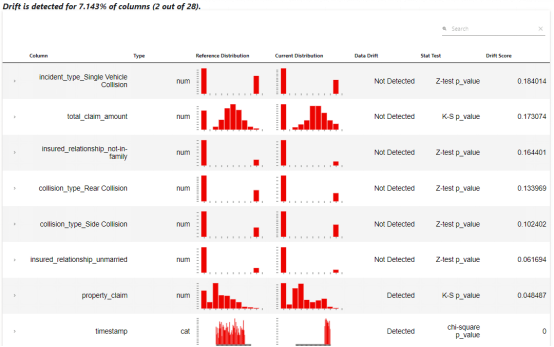
报告显示,列 “ property_claim ” 和 “ timestamp ” 确实检测到了漂移。这些信息可以 用 在MLOps管道中 以 重新训练模型,或者我们仍需要进一步的数据探索。
如果需要,我们也可以在日志字典对象中获取上述数据报告。
data_drift_report.as_dict() 接下来, 不妨 尝试从数据中训练分类器模型,并尝试使用 evidently 来监测模型性能。
from sklearn.ensemble import RandomForestClassifierrf = RandomForestClassifier()rf.fit(data.drop(['target', 'timestamp'], axis = 1), data['target']) evidently将 需要参考 数据集 和当前数据集中的目标列和预测列。 不妨 将模型预测添加到数据集中,并使用 evidently 来监测性能。
data['prediction'] = rf.predict(data.drop(['target', 'timestamp'], axis = 1))val['prediction'] = rf.predict(val.drop(['target', 'timestamp'], axis = 1)) 捎带提一下 ,最好 使用不是训练数据的参考数据来监测模型 性能。 不妨 使用以下代码 来 设置模型性能监测。
from evidently.metric_preset import ClassificationPresetclassification_performance_report = Report(metrics=[ ClassificationPreset(),])classification_performance_report.run(reference_data=data, current_data=val)classification_performance_report.show(mode='inline') 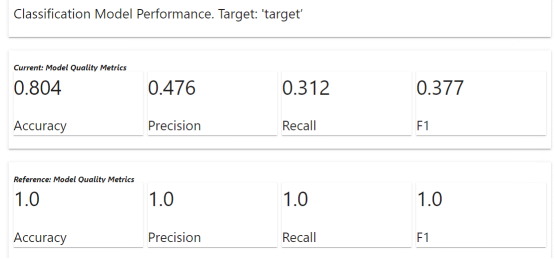
在结果中,我们得到的当前模型质量指标低于参考 (由于我们 使用训练数据作为参考 ,这在预料之中) 。 视 业务需求 而定 , 上述 度量 指标表明 我们需要采取的下一步。 不妨看看从evidently 报告中得到的其他信息。
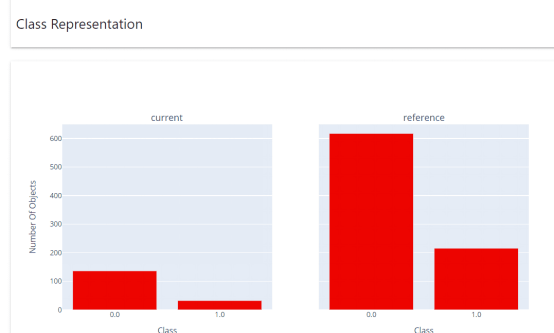
类Representation报告显示 了实际的类分布。
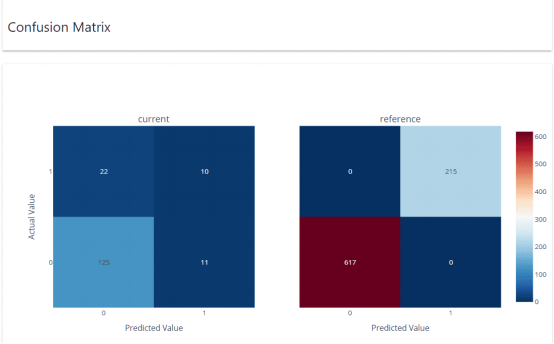
混淆矩阵显示了预测值与参考数据集和当前数据集中的实际数据的对比情况。
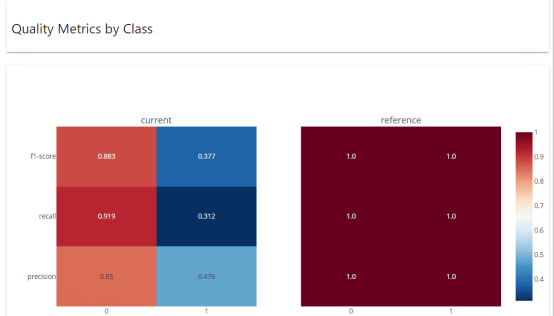
按类的质量度量 指标 显示 了 每个类的性能如何。
与前面一样,我们可以使用以下代码将分类性能报告转换 成 字典日志。
classification_performance_report.as_dict () 以上就是全 部内容。您可以在当前拥有的任何MLOps管道中设置模型性能监测 机制 ,它仍然可以很好地工作。
结语
模型性能监测是MLOps管道中的一项基本任务,帮助 确保 我们的模型跟上业务需求。使用一个名为 evidently 的Python 软件 包,我们 就能 轻松设置模型性能监测 机制 ,它可以 整合 到任何现有的MLOps管道中。
原文标题: Monitor Model Performance in the MLOps Pipeline with Python ,作者:Cornellius Yudha Wijaya









